
こんにちは。競プロerのみなさん。皆さんは自分以外の提出コードを参考にすることはありますか??
私は自力ACした問題でも、スッキリ書けなかったり、実行時間が長かった場合は、他の方のコードを見てコードをブラッシュアップするように意識しています。結構勉強になるのと、無駄を省いてリファクタリングしていくのが単純に楽しいです。
他の方のコードを見る時、ほとんどの方は実行時間やコード長でソートをかけて良さそうなコードを探しているのではないでしょうか??(自分がリスペクトしているユーザーを直接検索する方もいるかもしれませんね)
さて、私は気になりました。
コンスタントに実行時間が短いユーザーやコード長が短いユーザーは誰なのか??自分はどのレベルにいるのか?
ということで、提出コードの実行時間とコード長を解析して、提出コードのレベルが高い(実行時間が短い or コード長が短い)ユーザーを調査してみることにしました。
ついでにランキング形式にして、自分の順位も探ってみます。
なお、全ての言語でやりたいところですが、膨大な量になるのでユーザーが多いと思われるC++とPythonのみ紹介します。
本当は読みやすい・わかりやすいコード(を書く人)も探したいんですが、提出コードにいいねがつけられでもしない限り難しそうです。
やりたい事
- AtCoderで提出コードのレベルが高い人を見つける。
- 実行時間とコード長でレベルを測る
- ランキングも出す。
アプローチ
正直どういうアプローチをとるのがよいのか全くわからないので、素人発想で以下のようにアプローチしてみました。(より統計学的??にリーズナブル??な手法があればぜひ教えてください)
①各問題について、言語別に上位10%, 25%, 50%, 75%に相当する実行時間&コード長を調べる
②ユーザーのACコードの実行時間&コード長を調べる(複数ACコードがある場合は、それぞれ別個にベストの値を採用)
③あるユーザーがある問題にACしている時、以下の配点でポイントを得る。
- 上位10% 5
- 上位25% 4
- 上位50% 3
- 上位75% 2
- 上記以外 1
上記のルールでポイントを計算し、総合得点&平均得点を算出してランキングにしていきたいと思います。
解析する
あとはやるだけなので結果だけみたい人は一番下までどうぞ!
jupyter notebookをブログに貼り付けるのがうまくいかなかったので、少々見辛いかと思いますがご容赦ください。
提出コードのCSVを取得
AtCoderの提出コードを全部スクレイピングで取得すると膨大な時間がかかってしまうのですが、なんとAtCoder Problemsの開発者であるkenkooooさんがGitHubでcsvを公開してくれています。控えめに言って神の所業なので感謝しながら使わせてもらいましょう。こちらからダウンロードできます。
import pandas as pd
import numpy as np
data = pd.read_csv('./submissions.csv')
data = data.dropna()
data = data.astype({'execution_time': 'int32'})
print(data.size) # 113507010データ数はなんと1億超えです。おどろきですね。
以下、大した事ないpandasの処理がだらだら続きます。
各問題の実行時間とコード長の上位10, 25, 50, 75%を調査する
data_ac = data[data['result'] == 'AC'] # AC以外のコードを省きます
# 使わないカラムを落とします
list_for_exec = ['problem_id', 'language', 'execution_time']
list_for_leng = ['problem_id', 'language', 'length']
data_exec = data_ac[list_for_exec]
data_leng = data_ac[list_for_leng]
# 言語別、問題別にグループ化します
group_prob_lang_exec = data_exec.groupby(['language', 'problem_id'])
group_prob_lang_leng = data_leng.groupby(['language', 'problem_id'])以下のコードはおそらくもっとスマートな書き方があるはずです。
# execution_timeのmin, 10%, 25%, 50%, 75%を求めて一つのDataFrameにしていきます。
exec_statistics = group_prob_lang_exec.min().rename(columns={'execution_time': 'min'})
exec_statistics_10 = group_prob_lang_exec.quantile(0.1, interpolation='higher')
exec_statistics_25 = group_prob_lang_exec.quantile(0.25, interpolation='higher')
exec_statistics_50 = group_prob_lang_exec.quantile(0.50, interpolation='higher')
exec_statistics_75 = group_prob_lang_exec.quantile(0.75, interpolation='higher')
# なんとなく緩めの評価にしたかったので、interpolationはhigherにしました
exec_statistics['10%'] = exec_statistics_10['execution_time']
exec_statistics['25%'] = exec_statistics_25['execution_time']
exec_statistics['50%'] = exec_statistics_50['execution_time']
exec_statistics['75%'] = exec_statistics_75['execution_time']今の時点でこんな感じです。exec_statistics.head()
マイナー言語すぎてあまり変化がありませんが、一応それっぽくなっていますね。

同様の処理をlengthについても行います。
length_statistics = group_prob_lang_leng.min().rename(columns={'length': 'min'})
length_statistics_10 = group_prob_lang_leng.quantile(0.1, interpolation='higher')
length_statistics_25 = group_prob_lang_leng.quantile(0.25, interpolation='higher')
length_statistics_50 = group_prob_lang_leng.quantile(0.50, interpolation='higher')
length_statistics_75 = group_prob_lang_leng.quantile(0.75, interpolation='higher')
length_statistics['10%'] = length_statistics_10['length']
length_statistics['25%'] = length_statistics_25['length']
length_statistics['50%'] = length_statistics_50['length']
length_statistics['75%'] = length_statistics_75['length']以下のようになりました。length_statistics.head()

ユーザー別にACコードの得点を決める
各問題について言語別のボーダーラインが得られたので、続いてユーザーの情報を解析してスコアをつけていきます。
まずは、ユーザーが各問題に提出しているACコードの中から、言語別に実行時間・コード長のminを拾います。
# 不要なカラムを落とします
list_for_user_info = ['user_id', 'problem_id', 'language', 'length', 'execution_time']
pre_user_info = data_ac[list_for_user_info]
# ユーザーが複数のACコードを提出している場合に最小値を採用します
# このあとfor loopを回すのでas_indexをFalseにしています
group_user_lang_prob = pre_user_info.groupby(['user_id', 'language', 'problem_id'], as_index=False)
user_info = group_user_lang_prob.min()以下のようになっています。user_info.head()
上記のデータを用いてスコアをふっていきます。
なお、以下のコードの実行には私のPC(1.6 GHz Intel Core i5, メモリ8 GB)で約2時間かかっています。2千万行くらいでfor loopを使っているので仕方ない部分はあるのかもしれないんですが、どなたかここの処理をもっと速くするアイデアがありましたらぜひ教えてください。
(2020.0602追記)pandasの処理時間について勉強した上で最適化を行ったところ、2時間強かかっていた処理が20秒くらいまで短縮しました・・・・
iterrowsのfor loopは予想通り遅かったんですが、意外にもdf.locで行にアクセスする処理が遅いようです。
iterrowsのfor loopは、複数行を文字列結合させて1行に情報をまとめたあとに、map関数でまとめて行の処理を行うことで回避できます。またdf.locでの行アクセスについては一度pythonのdict型に変換することで高速化できます。
# 最適化前のコードです。めちゃめちゃ遅いです。
# スコアリング用の関数です
def get_score(value, border):
if value <= border['10%']:
return 5
elif value <= border['25%']:
return 4
elif value <= border['50%']:
return 3
elif value <= border['75%']:
return 2
else:
return 1
length_scores = []
exec_scores = []
for idx, row in user_info.iterrows():
# rowからそれぞれのデータを受け取ります
language = row['language']
problem_id = row['problem_id']
length = row['length']
exec_time = row['execution_time']
# languageとproblem_idからボーダーを取得します
length_border = length_statistics.loc[language, problem_id]
exec_border = exec_statistics.loc[language, problem_id]
# スコアを算出します
length_score = get_score(length, length_border)
exec_score = get_score(exec_time, exec_border)
length_scores.append(length_score)
exec_scores.append(exec_score)
user_info['length_score'] = length_scores
user_info['exec_score'] = exec_scores# 最適化後のコードです。上記コードの数百倍速くなりました。
def get_score_by_border(value, border):
if value <= border['10%']:
return 5
elif value <= border['25%']:
return 4
elif value <= border['50%']:
return 3
elif value <= border['75%']:
return 2
else:
return 1
# border取得のためにlanguageとproblem_idの2回にわけてアクセスすると
# 時間がかかるので文字列として結合してしまいます。
length_statistics['keys'] = length_statistics['language'] + length_statistics['problem_id']
# pandasのdf.locで行にアクセスするのはめちゃめちゃ遅い(pythonの辞書の100倍以上)のでdictにしてしまいます。
length_border_dict = length_statistics.set_index('keys').drop(['language', 'problem_id'], axis=1).to_dict(orient='index')
# execも同様に処理します。
exec_statistics['keys'] = exec_statistics['language'] + exec_statistics['problem_id']
exec_border_dict = exec_statistics.set_index('keys').drop(['language', 'problem_id'], axis=1).to_dict(orient='index')
# user_infoにも同様にkeys列を作成します。
user_info['keys'] = user_info['language'] + user_info['problem_id']
# keyとlengthのように複数列をまたぐと処理が遅くなるので、&で繋いで文字列にしてしまいます。
# あとでsplit('&')で分割すればそれぞれの値を得ることが可能です。
user_info['keys_length'] = user_info['keys'] + '&' + user_info['length'].astype('str')
user_info['keys_exec'] = user_info['keys'] + '&' + user_info['execution_time'].astype('str')
# dictとkeyとvalueからスコアリングを行います。
# クロージャでexec用とlength用を作り変えれるようにしてます。
def create_calcu_func(border_dict):
def calcurate_score(key_value):
key, value = key_value.split('&')
value = int(value)
border = border_dict[key]
score = get_score_by_border(value, border)
return score
return calcurate_score
# exec, lengthそれぞれのスコアリング用の関数を作ります。
calcu_exec_score = create_calcu_func(exec_border_dict)
calcu_length_score = create_calcu_func(length_border_dict)
# pandasの1列にアクセスして、mapで処理します。
length_scores = user_info['keys_length'].map(calcu_length_score)
exec_scores = user_info['keys_exec'].map(calcu_exec_score)
user_info['length_score'] = length_scores
user_info['exec_score'] = exec_scoresスコアをつけた状態が以下の表です。user_info.head()

集計していきましょう。
# 不要なカラムを落とします
user_status = user_info.loc[:, ['user_id', 'language', 'length_score', 'exec_score']]
# スコアの合計を求めます
user_scores = user_status.groupby(['user_id', 'language'], as_index=False).sum()
# ACが少ない人をフィルタリングしたいのでACカウントを求めます
user_ac_count = user_status.groupby(['user_id', 'language'], as_index=False).count()
user_scores['ac_count'] = user_ac_count['length_score'].values
# スコアの平均を求めます(groupby.mean()でもいいです)
user_scores['length_ave'] = user_scores['length_score'] / user_scores['ac_count']
user_scores['exec_ave'] = user_scores['exec_score'] / user_scores['ac_count']
# AC数でフィルターします(50という値に特に意味はありません)
filterd_user_scores = user_scores[user_scores['ac_count'] >= 50]結果は以下のようになりました。filterd_user_scores.head()
パッと見た感じはよさそうですね。
最後に言語でフィルタリングして、スコアでソートすればランキングの完成です。
さて、レベル(私の独自定義)が高いユーザーは誰なのでしょうか!!!???
結果発表
トータルスコアと平均スコアのランキングは以下のようになりました。
なお全体人数はPythonが35736名、 C++が83144名となっております。
注)AC数が50未満の方は集計から外しています。
Python 3.4.3 実行時間部門
Total Score (ExecutionTime)
python = filterd_user_scores['language'] == 'Python3 (3.4.3)'
python_ranking = filterd_user_scores[python]
list_for_exec_rank = ['user_id', 'language', 'exec_score', 'exec_ave', 'ac_count']
exec_score_ranking = python_ranking.sort_values('exec_score', ascending=False).reset_index()
exec_score_ranking.index = exec_score_ranking.index + 1
exec_score_ranking[list_for_exec_rank].head(20)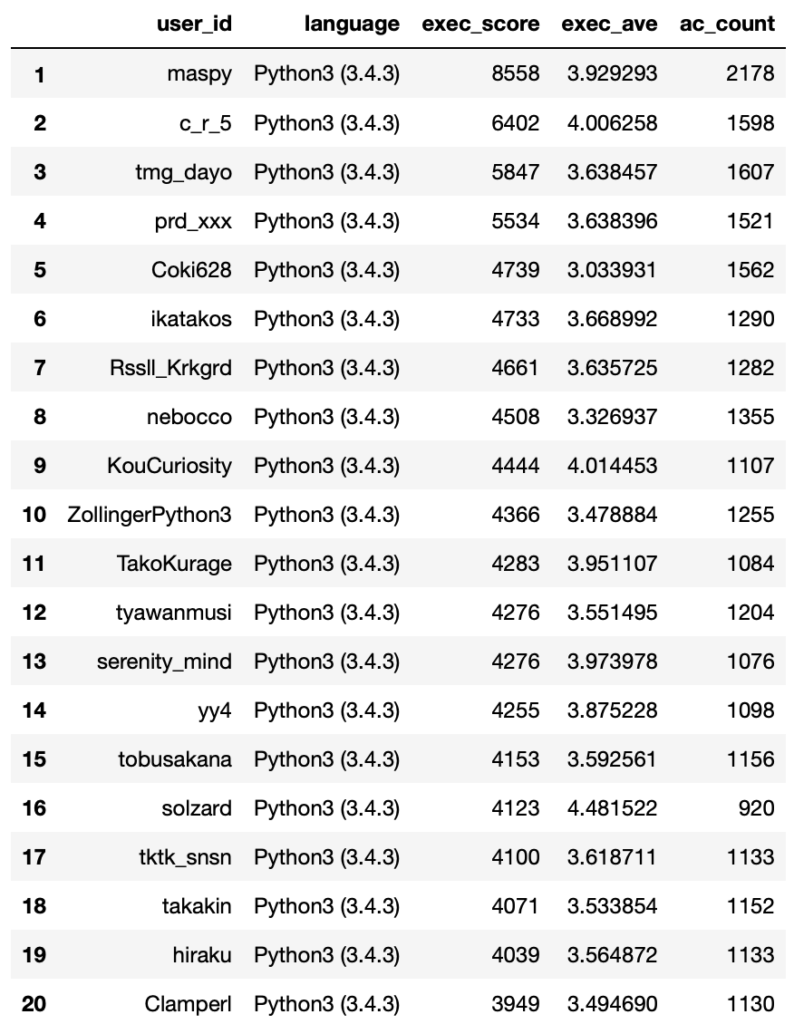
Python 実行時間部門トータルスコア1位は圧倒的なAC数と3.92という高いアベレージスコアを叩き出したmaspyさんでした。
トータルスコアなのでAC数にかなり比例するのですが、16位のsolzardさんのようにAC数が他の方と比べて200近く低くても、4.48という飛び抜けたアベレージで上位にくいこんでいる方もいますね。
Average Score (ExecutionTime)
exec_ave_ranking = python_ranking.sort_values('exec_ave', ascending=False).reset_index()
exec_ave_ranking.index = exec_ave_ranking.index + 1
exec_ave_ranking[list_for_exec_rank].head(20)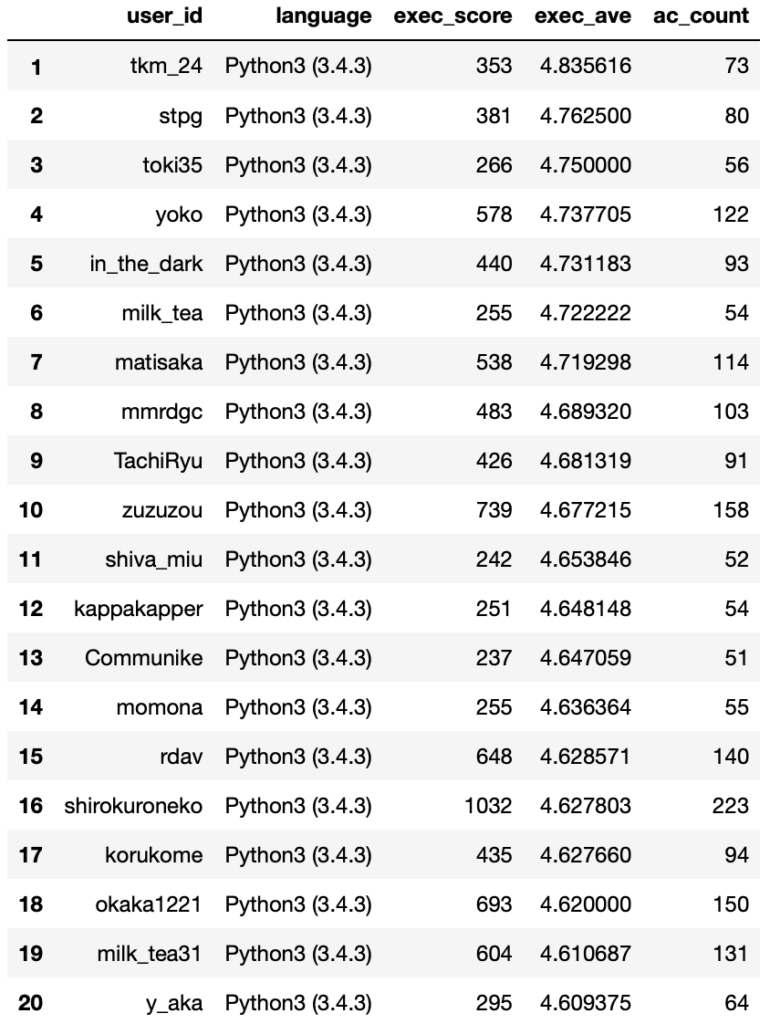
Python 実行時間部門アベレージスコア1位はtkm-24さんで4.83ポイントでした。
アベレージスコアのランキングでは上位のAC数が比較的少ない値となっていました。
今回の集計ではO(1)問題のように実行時間に差がつきにくい問題では労せず満点の5点が取得できます。このため、例えばABCのA, B問題をメインで解いているとおそらく平均点もかなり高くなると予想されます。
より納得感のあるスコアリングのために、例えば問題の難易度や得点に応じてスコアに係数をかけるなどする必要があるかもしれませんね。
その他、各問題の上位x%というボーダーでスコアリングするのではなく、平均値と標準偏差を元に、偏差値でスコアリングするような手法もありでしょうか。
あるいは単純にACカウントの下限を100や200に増やすという方法でもいいかもしれません。
アイデアがある方は実際にやってみて結果を教えてください!もし面倒ならコメントいただければ私の方で実装してみます。(時間かかるかもしれませんが)
ちなみに冒頭でコードのブラッシュアップをしています(キリッ とほざいていた私のレベルはというと
me = exec_ave_ranking['user_id'] == 'parsely'
exec_ave_ranking[me]
1809位 / 35736 でした。結構意識していたはずなんですが、4.0にとどいていなかったのは悔しいところです。もっとブラッシュアップしていきたいですね。
Python 3.4.3 コード長部門
Total Score (CodeLength)
list_for_length_rank = ['user_id', 'language', 'length_score', 'length_ave', 'ac_count']
length_score_ranking = python_ranking.sort_values('length_score', ascending=False).reset_index()
length_score_ranking.index = length_score_ranking.index + 1
length_score_ranking[list_for_length_rank].head(20)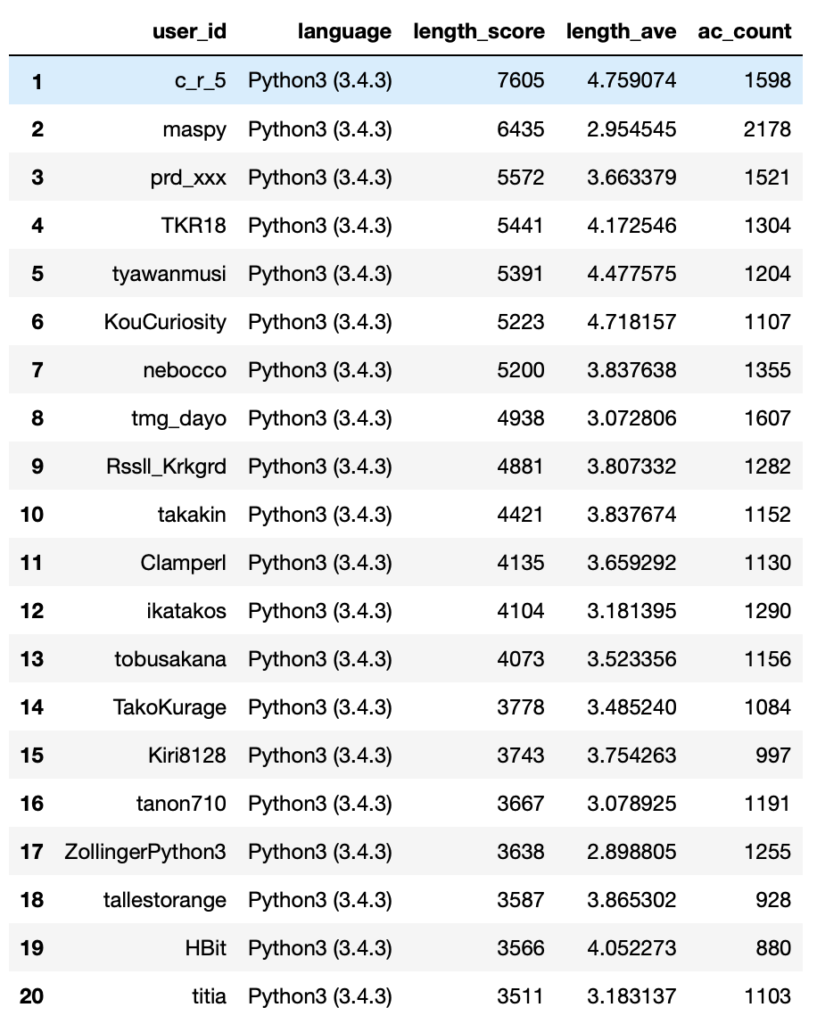
Python コード長部門トータルスコア1位は600近いACの差を、4.75という高いアベレージスコアで巻き返したc_r_5さんでした。
提出コードをコード長でソートするとよく見かける方なので、納得の結果ですね。(同時に今回の集計がおそらく正常に動作している安心材料にもなりました)
Average Score (CodeLength)
length_ave_ranking = python_ranking.sort_values('length_ave', ascending=False).reset_index()
length_ave_ranking.index = length_ave_ranking.index + 1
length_ave_ranking[list_for_length_rank].head(20)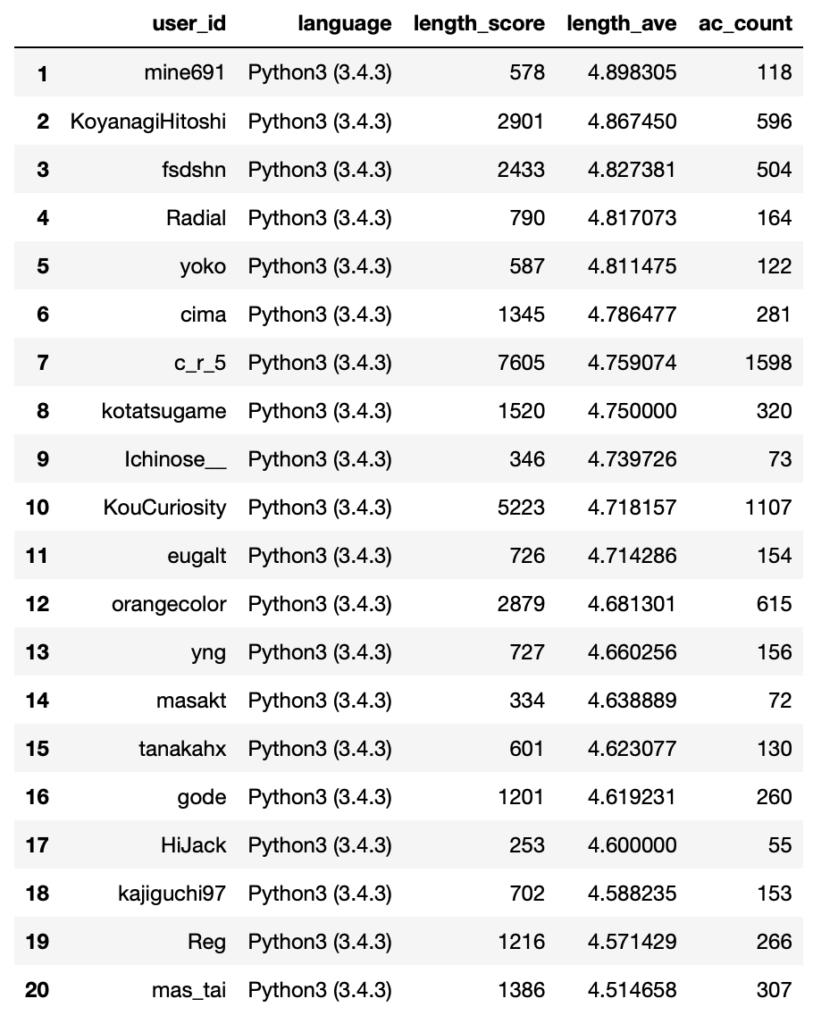
Python コード長部門アベレージスコア1位はmine691さんでした。勝手にc_r_5さんがアベレージも1位かと思っていたんですが、短いコードを極めているかたが他にもたくさんいらっしゃって驚きです。
C++14 (GCC 5.4.1) 実行時間部門
以下コードは省略して結果だけ記載していきます。
Total Score (ExecutionTime)
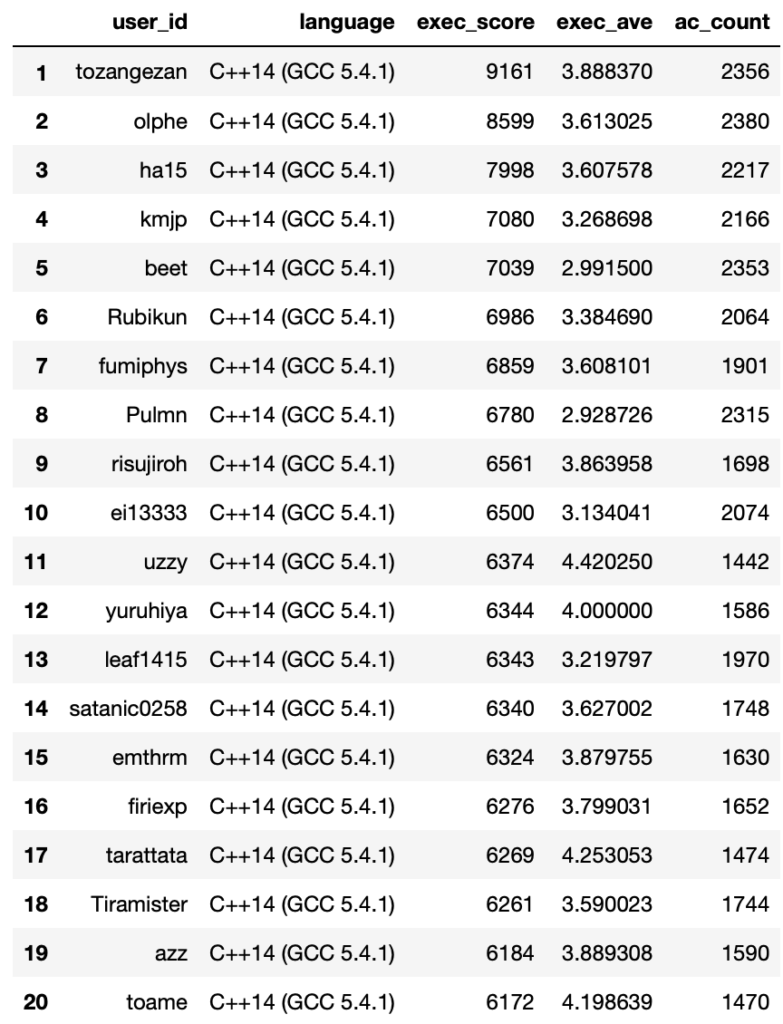
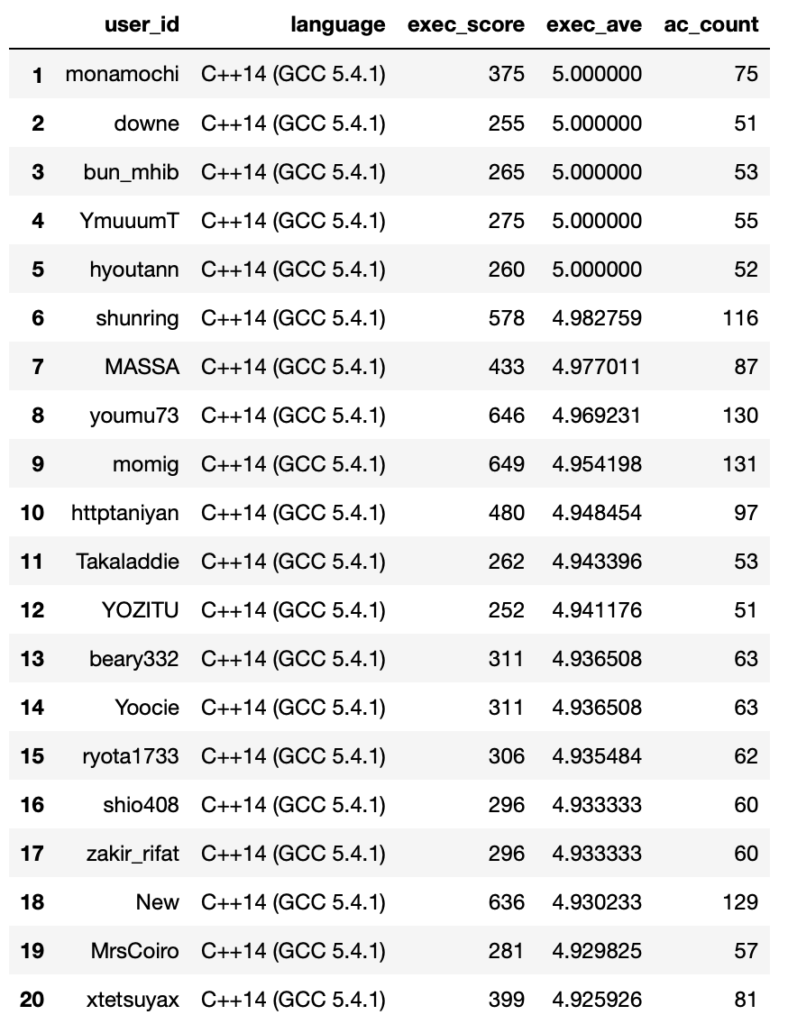
Average Score (ExecutionTime)
C++14 (GCC 5.4.1) コード長部門
Total Score (CodeLength)
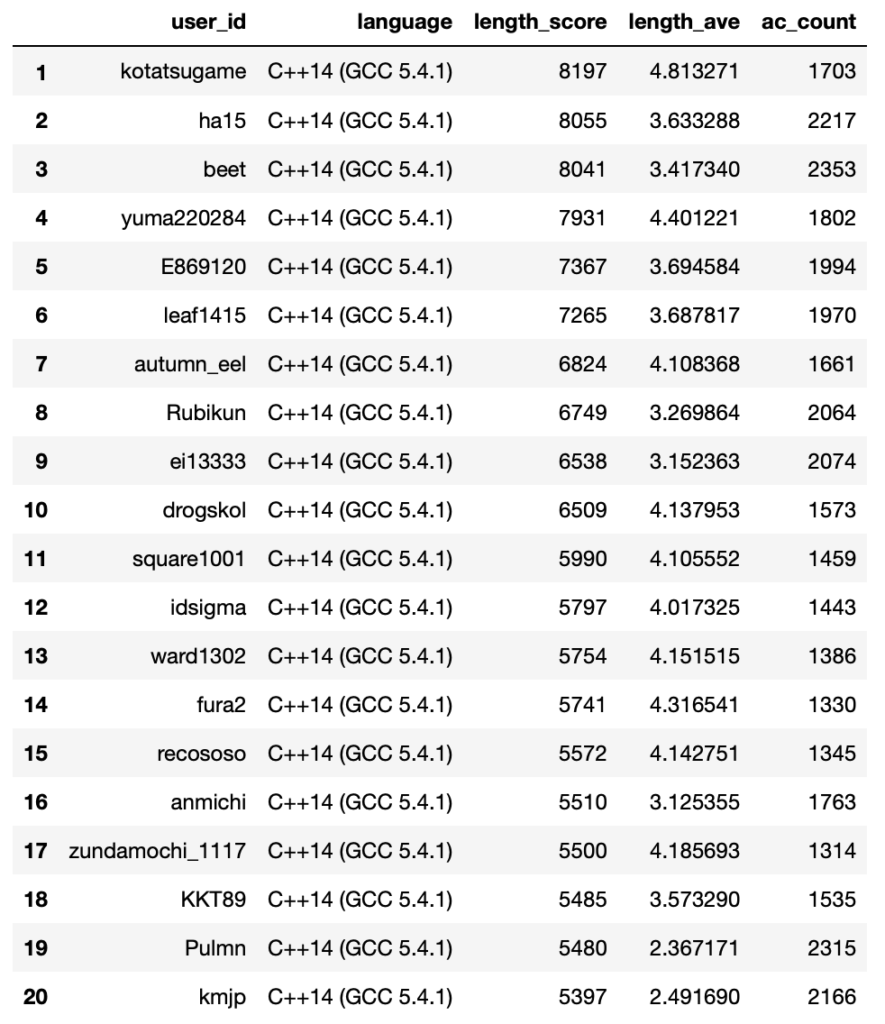
Average Score (CodeLength)
さいごに
皆さん様々なモチベーションで競技プログラミングに励んでいるかと思います。
私はステータスが高くなったりランクが上がったりするのがとても好きで、Atcoderのレーティング推移は競技プログラミングのモチベーションの一つです。(もしレーティングがなかったらそれほどハマってなかったかもしれません。)
今回はすこし変わった視点で、ユーザーのある種のステータスを表示するという試みを行いました。
競技プログラミングのモチベーションの1つに、今回のようなステータスの視点をとりいれてみるのはいかがでしょうか??
ちなみに、こういったステータスがわかるwebアプリを開発中です。とても難しいです。。。。
次はこういったステータスがレーティングとどの程度相関があるのかを解析してみたいと思います。


コメント